


Binary Search Tree
(+ Java Code Examples)
There is only one data structure that allows you to quickly both find elements by their key - and iterate over its elements in key order: the binary search tree!
In this article, you will learn:
- What is a binary search tree?
- How do you add new elements, how do you search for them, and how do you delete them?
- How to iterate over all elements of the binary search tree?
- How do you implement a binary search tree in Java?
- What is the time complexity of the binary search tree operations?
- What distinguishes the binary search tree from similar data structures?
You can find the source code for the article in this GitHub repository.
Binary Search Tree Definition
A binary search tree (BST) is a binary tree whose nodes contain a key and in which the left subtree of a node contains only keys that are less than (or equal to) the key of the parent node, and the right subtree contains only keys that are greater than (or equal to) the key of the parent node.
The binary search tree data structure makes it possible to quickly¹ insert, look up and remove keys (like a Set in Java).
To find a node, you have to – starting at the root node – compare the search key with the node's key. The following three cases can occur:
- The search key is equal to the node's key: you have reached the target node.
- The search key is smaller than the node's key: the search must continue in the left subtree.
- The search key is greater than the node's key: the search must continue in the right subtree.
The nodes can also contain a value besides the key. You can then not only check whether the binary search tree contains a key. You can also assign a value to the key and retrieve it via the key (like in a Map).
The placement of the nodes in the binary search tree also makes it possible to iterate very efficiently over the keys and their values in key order.
¹ "Quickly" means that time complexity O(log n) is achieved in the best case. Read more about this in the sections Balanced Binary Search Tree and Time Complexity.
Binary Search Tree Example
Here you can see an example of a binary search tree:
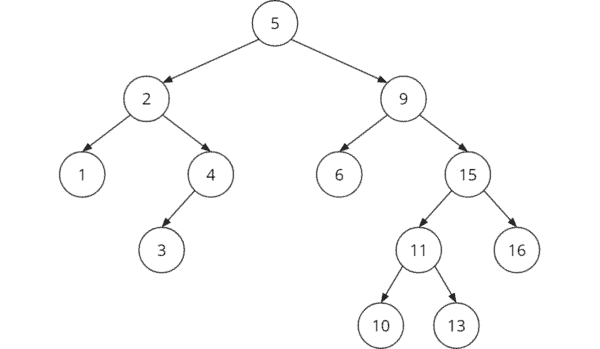
To find key 11 in this example, one would proceed as follows:
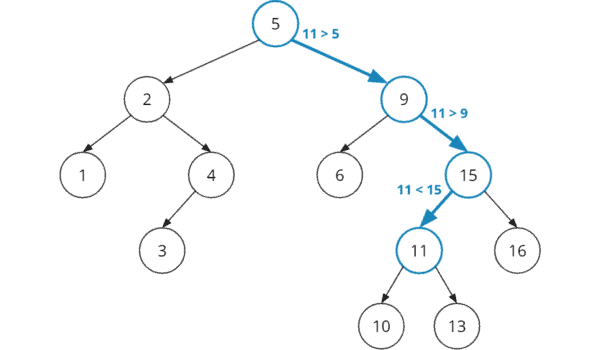
- Step 1: Compare search key 11 with root key 5. 11 is greater, so the search must continue in the right subtree.
- Step 2: Compare search key 11 with node key 9 (right child of 5). 11 is greater. Therefore, the search must continue in the right subtree under the 9.
- Step 3: Compare search key 11 with node key 15 (right child of 9). 11 is less. Therefore, the search must continue in the left subtree under the 15.
- Step 4: Compare search key 11 with node key 11 (left child of 15). We've found the node we were looking for.
In the following diagram, I've highlighted the four steps with nodes and edges marked in blue:
Binary Search Tree Properties
The most important property of a binary search tree is fast access to a node via its key. The effort required to do this depends on the tree's structure: nodes that are close to the root are found after fewer comparisons than nodes that are far from the root.
Depending on the intended use of the binary search tree, there are different requirements for its shape. For certain applications, the height of the binary search tree should be as low as possible (see section Balanced Binary Search Tree).
For other uses, it is more important that frequently accessed keys are close to the root, while the depth of nodes that are accessed less frequently is not so important (see section Optimal Binary Search Tree).
Balanced Binary Search Tree
A balanced binary search tree is a binary search tree in which the left and right subtrees of each node differ in height by at most one.
The example tree shown above is not balanced. The left subtree of node "9" has a height of one, and the right subtree has a height of three. The height difference is, therefore, greater than one.
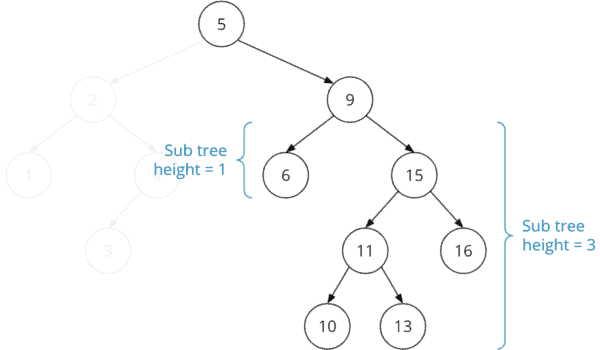
We can calculate how many comparisons we need on average to find a key in this tree. To do this, we multiply the number of nodes at each node level by the number of comparisons we need to reach a node at that level:
| Number of comparisons (= node depth + 1) | Number of nodes on this level | Number of comparisons at this level |
|---|---|---|
| 1 (root) | 1 (5) | 1 × 1 = 1 |
| 2 | 2 (2, 9) | 2 × 2 = 4 |
| 3 | 4 (1, 4, 6, 15) | 3 × 4 = 12 |
| 4 | 3 (3, 11, 16) | 4 × 3 = 12 |
| 5 | 2 (10, 13) | 5 × 2 = 10 |
| Totals: | 12 | 39 |
If we were to search for each node exactly once, we would need a total of 39 comparisons. 39 comparisons divided by 12 nodes = 3.25 comparisons per node. So, on average, we need 3.25 comparisons to find a node.
The following example tree contains the same keys but is balanced:

We perform the same calculation for the balanced search tree:
| Number of comparisons (= node depth + 1) | Number of nodes on this level | Number of comparisons at this level |
|---|---|---|
| 1 (root) | 1 (5) | 1 × 1 = 1 |
| 2 | 2 (2, 11) | 2 × 2 = 4 |
| 3 | 4 (1, 4, 9, 15) | 3 × 4 = 12 |
| 4 | 5 (3, 6, 10, 13, 16) | 4 × 5 = 20 |
| Totals: | 12 | 37 |
We only need 37 comparisons for 12 nodes in the balanced tree, which is 3.08 comparisons per node.
Degenerate Binary Tree
The binary search tree structure results primarily from the order in which we insert and delete nodes. In an extreme case – if nodes are inserted in ascending or descending order – a tree like the following could result:

If – as in this example – each inner node has exactly one child, so that a tree structure is no longer recognizable, we speak of a degenerate tree.
If we were to search every node in this tree once, we would come up with
1×1 (for the 1)
+ 1×2 (for the 2)
+ 1×3 (for the 3)
...
+ 1×10 (for the 13)
+ 1×11 (for the 15)
+ 1×12 (for the 16)
= 78 comparisons
... for 12 nodes. On average, we would therefore need 78 / 12 = 6.5 comparisons to find any key – significantly more than in the randomly arranged and balanced search trees.
Self-Balancing Binary Search Tree
A self-balancing (also height-balanced) binary search tree transforms itself when inserting and deleting keys to keep the tree's height as small as possible.
"As small as possible" is not specified. A self-balancing binary search tree does not necessarily have to achieve the properties of a balanced binary search tree. (The height difference of a node's left and right subtree may also be greater than one).
Since the reorganization of the tree involves a certain amount of time and space overhead, it is important to find a balance between effort and result.
There are numerous implementations of self-balancing binary search trees. Among the best known are the AVL tree and the red-black tree.
Optimal Binary Search Tree
In the balanced binary search tree described above, the average cost of accessing arbitrary nodes is minimized. This is useful when the search for all keys is approximately uniformly distributed (or unknown).
There are also use-cases where we know that specific nodes are accessed more often than others. An example would be a dictionary used for spell checking. The nodes of the frequently used words are accessed more often than the nodes of the rarely used words.
Thus, to minimize search costs – the number of comparisons – overall, it would make sense to place nodes with frequently used words closer to the root than nodes with rarely used words.
If we know in advance how often (or with what probability) each key of the binary search tree will be accessed, we can construct the tree so that the search cost for the entirety of searches is minimal. Such a tree is called an optimal binary search tree.
Optimal Binary Search Tree – Example
The following example uses a dictionary with a few words and their frequencies in a text corpus (source: WaCky). The example will show how the total cost differs between balanced and optimal binary search trees.
| Word | Frequency in the text corpus |
|---|---|
| the | 95,630,829 |
| of | 56,069,188 |
| with | 12,745,509 |
| your | 4,445,177 |
| its | 2,492,768 |
| after | 1,313,160 |
| level | 607,485 |
| news | 285,837 |
| hotel | 154,219 |
| block | 82,216 |
| false | 59,442 |
| lane | 25,898 |
A balanced binary search tree with the words listed could have the following structure, for example:

Since we know how often each word is looked up, we can calculate the average cost per call:
| Number of comparisons (node depth + 1) | Word frequencies at this depth | Sum of word frequencies at this depth | Number of comparisons × sum of word frequencies |
|---|---|---|---|
| 1 (root) | 25,898 (lane) | 25,898 | 1 × 25,898 = 25,898 |
| 2 | 59,442 (false) + 95,630,829 (the) | 95,690,271 | 2 × 95,690,271 = 191,380,542 |
| 3 | 82,216 (block) + 2,492,768 (its) + 285,837 (news) + 12,745,509 (with) | 15,606,330 | 3 × 15,606,330 = 46,818,990 |
| 4 | 1,313,160 (after) + 154,219 (hotel) + 607,485 (level) + 56,069,188 (of) + 4,445,177 (your) | 62,589,229 | 4 × 62,589,229 = 250,356,916 |
| Totals: | 173,911,728 | 488,582,346 |
In this balanced tree, we need an average of
488,582,346 / 173,911,728 = 2.81 comparisons per search.
Notice that the root of the tree contains the rarely used word "lane". Frequently used words such as "of" and "with", on the other hand, lie rather far down the tree.
If we optimize the tree so that frequently used words are closer to the root, we achieve the following structure:

You can see at first glance that this tree is no longer balanced. Instead, the most frequently used words "the", "of", "width" are in the first two levels of the tree. And the most rarely used words "lane", "false", and "block" are very far down.
Let's calculate the average cost again:
| Number of comparisons (node depth + 1) | Word frequencies at this depth | Sum of word frequencies at this depth | Number of comparisons × sum of word frequencies |
|---|---|---|---|
| 1 (root) | 95,630,829 (the) | 95,630,829 | 1 × 95,630,829 = 95,630,829 |
| 2 | 56,069,188 (of) + 12,745,509 (with) | 68,814,697 | 2 × 68,814,697 = 137,629,394 |
| 3 | 2,492,768 (its) + 4,445,177 (your) | 6,937,945 | 3 × 6,937,945 = 20,813,835 |
| 4 | 1,313,160 (after) + 607,485 (level) | 1,920,645 | 4 × 1,920,645 = 7,682,580 |
| 5 | 154,219 (hotel) + 25,898 (lane) + 285,837 (news) | 465,954 | 5 × 465,954 = 2,329,770 |
| 6 | 82,216 (block) | 82,216 | 6 × 82,216 = 493,296 |
| 7 | 59,442 (false) | 59,442 | 7 × 59,442 = 416,094 |
| Totals: | 173,911,728 | 264,995,798 |
In the optimal binary search tree, we need on average
264,995,798 / 173,911,728 = 1.52 comparisons per search.
So the search is almost twice as fast as in the balanced tree.
You can read about how to construct an optimal binary search tree on Techie Delight, for example.
Binary Search Tree in Java
To implement a binary search tree in Java, we use the same basic data structure as for the Java implementation of the binary tree.
Nodes are defined in the Node class. We store the key in the data field. For simplicity, we use int primitives instead of concrete or generic classes.
public class Node {
int data;
Node left;
Node right;
public Node(int value) {
this.value = value;
}
}Code language: Java (java)In this article – and in the further course of the tutorial series – we will implement different types of binary search trees. Therefore, we define an interface BinarySearchTree, which extends the interface BinaryTree created in the first part of the series (and which provides a single method: getRoot()):
public interface BinaryTree {
Node getRoot();
}
public interface BinarySearchTree extends BinaryTree {
// operations will be added soon...
}Code language: Java (java)In the course of this article, the BinarySearchTree interface will be implemented by the following two classes:
BinarySearchTreeIterative– an iterative implementation of the binary search treeBinarySearchTreeRecursive– a recursive implementation of the binary search tree
Both classes extend BaseBinaryTree, a minimal binary tree implementation containing only the reference to the root node:
public class BaseBinaryTree implements BinaryTree {
protected Node root;
@Override
public Node getRoot() {
return root;
}
}
public class BinarySearchTreeIterative extends BaseBinaryTree
implements BinarySearchTree {
// operations will be added soon...
}
public class BinarySearchTreeRecursive extends BaseBinaryTree
implements BinarySearchTree {
// operations will be added soon...
}Code language: Java (java)The following UML class diagram shows the interfaces and classes created for the binary search tree data structure:

Don't be surprised that the BinarySearchTree interface and the implementing classes are still empty – it won't stay that way for long. In the following sections, I will introduce the different operations on binary search trees and add them to the code step by step.
Binary Search Tree Operations
Binary search trees provide operations for inserting, deleting, and searching keys (and possibly associated values), as well as traversing over all elements.
Searching
I have shown in detail how searching works in the introduction and with an example. In summary: we compare the search key with the node keys starting at the root and repeatedly follow the left or right child node, depending on whether the search key is less than or greater than the respective node key – until we have found the node with the searched key.
Searching – Java Source Code (Recursive)
The Java code for the search in the BST (abbreviation for "binary search tree") can be implemented recursively and iteratively. Both variants are straightforward. The recursive variant can be found in the class BinarySearchTreeRecursive starting at line 10:
public Node searchNode(int key) {
return searchNode(key, root);
}
private Node searchNode(int key, Node node) {
if (node == null) {
return null;
}
if (key == node.data) {
return node;
} else if (key < node.data) {
return searchNode(key, node.left);
} else {
return searchNode(key, node.right);
}
}Code language: Java (java)The code should be self-explanatory.
Searching – Java Source Code (Iterative)
The iterative variant (BinarySearchTreeIterative starting at line 10) is just as easy. Instead of calling the search recursively on the subtrees, the node reference walks along the examined nodes until the one with the searched key is found and returned.
public Node searchNode(int key) {
Node node = root;
while (node != null) {
if (key == node.data) {
return node;
} else if (key < node.data) {
node = node.left;
} else {
node = node.right;
}
}
return null;
}Code language: Java (java)Binary Search Tree Insertion
When inserting a key into the binary search tree, one must ensure that the order of the keys is preserved. How exactly this is achieved depends on the specific implementation. Self-balancing binary search trees employ complex algorithms, which I will discuss in later articles in the series.
We begin by implementing a non-self-balancing search tree that does not allow duplicates. Inserting new keys works as follows:
Just as with the search, we follow the nodes – starting at the root – to the left if the key to insert is less than the node key – and to the right if the key to insert is greater than the node key. At some point, we reach a leaf node. If the key to be inserted is less than the leaf key, we insert a new node as the left child of the leaf; if the key to be inserted is greater than the leaf key, we insert the new node as the right child.
(If we find a node whose key is the same as the key to be inserted, we cancel the insertion attempt with an error message. This is because duplicates are not allowed.)
The following diagram shows how we insert key 8 into the example tree from the beginning of the article:

The insert operation proceeds as follows:
- It compares the 8 with the root key 5. The 8 is greater, so it continues with the root's right child, the 9.
- It compares the 8 with the 9. The 8 is less, so the operation moves to the left child of the 9, which is the 6.
- It compares the 8 with the 6. The 8 is greater. The 6 has no right child. Therefore, the operation appends a new node with the new key 8 as the right child to the 6.
Binary Search Tree Insertion – Java Source Code (Iterative)
We can also implement insertion both recursively and iteratively. I will start with the iterative implementation. It's a bit longer but easier to understand than the recursive one. You can find the iterative insert operation in BinarySearchTreeIterative starting at line 26:
public void insertNode(int key) {
Node newNode = new Node(key);
if (root == null) {
root = newNode;
return;
}
Node node = root;
while (true) {
// Traverse the tree to the left or right depending on the key
if (key < node.data) {
if (node.left != null) {
// Left sub-tree exists --> follow
node = node.left;
} else {
// Left sub-tree does not exist --> insert new node as left child
node.left = newNode;
return;
}
} else if (key > node.data) {
if (node.right != null) {
// Right sub-tree exists --> follow
node = node.right;
} else {
// Right sub-tree does not exist --> insert new node as right child
node.right = newNode;
return;
}
} else {
throw new IllegalArgumentException("BST already contains a node with key " + key);
}
}
}Code language: Java (java)We start by creating the new node. If the root node is not already set, we set it to the new node.
Otherwise, we follow the nodes in the while loop starting from the root until we find the node under which the new node is to be inserted as a left or right child. The actual insertion is done within the loop since we still know at that point whether the new node is to be inserted as a left or right child.
Binary Search Tree Insertion – Java Source Code (Recursive)
You can find the much shorter, recursive solution in BinarySearchTreeRecursive starting at line 29:
public void insertNode(int key) {
root = insertNode(key, root);
}
Node insertNode(int key, Node node) {
// No node at current position --> store new node at current position
if (node == null) {
node = new Node(key);
}
// Otherwise, traverse the tree to the left or right depending on the key
else if (key < node.data) {
node.left = insertNode(key, node.left);
} else if (key > node.data) {
node.right = insertNode(key, node.right);
} else {
throw new IllegalArgumentException("BST already contains a node with key " + key);
}
return node;
}Code language: Java (java)In this variant, we search for the insertion position recursively. The recursive method returns the new node if the method was called on a null reference. The caller then sets the node.left or node.right reference to the returned node.
If, on the other hand, the recursive method is called on an existing node, then (after further descent into and ascent out of the recursion) that existing node is returned. In this case, the assignment to node.left or node.right does not result in any change.
Binary Search Tree Deletion
Just as with inserting nodes, the specific approach to deleting them depends on the implementation. Self-balancing search trees use complex algorithms to maintain balance. We first implement a simple solution. As with binary trees in general, we have to distinguish three cases:
Case A: Deleting a Node Without Children (Leaf)
If the key to be deleted is on a leaf, we can simply remove it from the tree. This does not change the order of the remaining nodes. To do this, we set the left or right reference of the parent node that points to the node to be deleted to null.
In the following example, we remove the node with the key 10 from the example tree of this article. For the sake of clarity, the diagram shows only the right subtree:

Case B: Deleting a Node With One Child (Half Leaf)
If we want to delete a node with exactly one child from the binary search tree, the child moves up to the deleted position. This preserves the order of all other nodes.
The following example shows how, after deleting 10 in the previous step, we now also delete the node with the key 11. We set the left or right reference of the parent node (15 in the example) to the child of the deleted node (13 in the example).
The 13 moves up to the deleted position:

Case C: Deleting a Node With Two Children
If we want to delete a node with two children from a binary search tree, it gets a bit more complicated. A common approach is the following:
- We determine the node with the smallest key in the right subtree. This is the so-called "in-order successor" of the node to be deleted.
- We copy the data from the in-order successor to the node to be deleted.
- We remove the in-order successor from the right subtree. Since this is the node with the smallest key of the right subtree, it cannot have a left child. So it either has no child at all or only one right child. Accordingly, we can remove the in-order successor as in case A or B.
In the following example, we delete root node 5 by having in-order successor 6 take its position:

Alternatively, you can use the in-order predecessor of the left subtree to replace the deleted node. An intelligent selection of in-order predecessor or successor increases the probability that the tree becomes (and remains) reasonably balanced.
Binary Search Tree Deletion – Java Source Code (Recursive)
Like all other operations, deleting from the binary search tree can be implemented recursively and iteratively. If you understand the recursive method for insertion, it will be easier to start with the recursive method for deletion as well. You can find it in BinarySearchTreeRecursive starting at line 52:
public void deleteNode(int key) {
root = deleteNode(key, root);
}
Node deleteNode(int key, Node node) {
// No node at current position --> go up the recursion
if (node == null) {
return null;
}
// Traverse the tree to the left or right depending on the key
if (key < node.data) {
node.left = deleteNode(key, node.left);
} else if (key > node.data) {
node.right = deleteNode(key, node.right);
}
// At this point, "node" is the node to be deleted
// Node has no children --> just delete it
else if (node.left == null && node.right == null) {
node = null;
}
// Node has only one child --> replace node by its single child
else if (node.left == null) {
node = node.right;
} else if (node.right == null) {
node = node.left;
}
// Node has two children
else {
deleteNodeWithTwoChildren(node);
}
return node;
}Code language: Java (java)In the first lines (up to the comment "At this point…"), we search for the delete position by recursively calling the deleteNode() method if the key to be deleted is less than or greater than that of the node currently under consideration.
Once we have found the node to delete and it has no children, the method returns null. The caller then sets the left or right reference of the parent node to null accordingly.
If the node to be deleted has exactly one child, the method returns this very child. The caller sets the left or right reference of the parent node to the returned child. As a result, the node to be deleted is removed from the tree.
If the node to be deleted has two children, we call the following method:
private void deleteNodeWithTwoChildren(Node node) {
// Find minimum node of right subtree ("inorder successor" of current node)
Node inOrderSuccessor = findMinimum(node.right);
// Copy inorder successor's data to current node
node.data = inOrderSuccessor.data;
// Delete inorder successor recursively
node.right = deleteNode(inOrderSuccessor.data, node.right);
}
private Node findMinimum(Node node) {
while (node.left != null) {
node = node.left;
}
return node;
}Code language: Java (java)First, we search for the in-order successor using the findMinimum() method. We copy its data into the node to be deleted. Then we remove the in-order successor from the right subtree of the node to be deleted by recursively calling deleteNode().
Binary Search Tree Deletion – Java Source Code (Iterative)
The iterative method is much longer because to delete the in-order successor, we cannot simply call the delete method recursively. You can find the iterative implementation in BinarySearchTreeIterative starting at line 62:
public void deleteNode(int key) {
Node node = root;
Node parent = null;
// Find the node to be deleted
while (node != null && node.data != key) {
// Traverse the tree to the left or right depending on the key
parent = node;
if (key < node.data) {
node = node.left;
} else {
node = node.right;
}
}
// Node not found?
if (node == null) {
return;
}
// At this point, "node" is the node to be deleted
// Node has at most one child --> replace node by its single child
if (node.left == null || node.right == null) {
deleteNodeWithZeroOrOneChild(key, node, parent);
}
// Node has two children
else {
deleteNodeWithTwoChildren(node);
}
}Code language: Java (java)In the first half of the method (up to the comment "At this point…"), we search for the node to be deleted – just like in the iterative search and insert operations. In doing so, we remember its parent node.
We then remove a leaf or half leaf with the deleteNodeWithZeroOrOneChild() method:
private void deleteNodeWithZeroOrOneChild(int key, Node node, Node parent) {
Node singleChild = node.left != null ? node.left : node.right;
if (node == root) {
root = singleChild;
} else if (key < parent.data) {
parent.left = singleChild;
} else {
parent.right = singleChild;
}
}Code language: GLSL (glsl)Depending on whether the node to be deleted is the left or right child of its parent, the left or right reference of the parent is set to the remaining child of the node to be deleted. If the node to be deleted has no child, then child is null, and accordingly, the left or right reference of the parent is also set to null.
If the node to be deleted has two children, then the method deleteNodeWithTwoChildren() is called:
private void deleteNodeWithTwoChildren(Node node) {
// Find minimum node of right subtree ("inorder successor" of current node)
Node inOrderSuccessor = node.right;
Node inOrderSuccessorParent = node;
while (inOrderSuccessor.left != null) {
inOrderSuccessorParent = inOrderSuccessor;
inOrderSuccessor = inOrderSuccessor.left;
}
// Copy inorder successor's data to current node
node.data = inOrderSuccessor.data;
// Delete inorder successor
// Case a) Inorder successor is the deleted node's right child
if (inOrderSuccessor == node.right) {
// --> Replace right child with inorder successor's right child
node.right = inOrderSuccessor.right;
}
// Case b) Inorder successor is further down, meaning, it's a left child
else {
// --> Replace inorder successor's parent's left child
// with inorder successor's right child
inOrderSuccessorParent.left = inOrderSuccessor.right;
}
}Code language: Java (java)As with the recursive variant, we first search for the in-order successor and copy its data to the node to be deleted.
However, removing the in-order successor from the right subtree is more complex in the iterative variant. We must distinguish two cases here:
- The in-order successor is the right child of the node to be deleted, i.e., the root of the right subtree. In this case, the right child of the node to be deleted is replaced with the right child of the in-order successor.
- The in-order successor is further down the right subtree. In this case, it is the left child of its parent node and is replaced with its right child.
Binary Search Tree Traversal
Just as with binary trees in general, you can perform pre-order, post-order, in-order, reverse-in-order, and level-order traversals in a binary search tree.
You can learn what these traversal types mean and how they are implemented in Java in the binary tree traversal section of the article on binary trees.
While pre-, post-, and level-order are not very useful, in-order traversal is extremely helpful in binary search trees: it iterates over all the tree's nodes in sort order of their keys:

The traversal classes DepthFirstTraversal, DepthFirstTraversalIterative, and DepthFirstTraversalRecursive presented in the previous article can be applied unchanged to instances of BinarySearchTree, since it transitively implements the interface BinaryTree.
Validate a Binary Search Tree
There are situations where we have a binary tree, and we need to check if it is a valid binary search tree.
The obvious solution – to recursively check whether each node is greater than its left child and less than its right child – is unfortunately incorrect. This property would also apply to the following binary tree, for example:

In this example, the 6 is less than the 12 – so far, so good. However, it is located in the right subtree below the 8. This subtree may only contain keys that are greater than 8. Since this does not apply to the 6, the requirements for a valid BST are not fulfilled.
Instead, we have two options:
- We perform a regular pre-order traversal and check whether the key order is maintained, i.e., whether the key of a node is greater than (or equal to) the key of the predecessor node.
- We recursively check – starting from the root – the left and right subtree of each node, specifying a range of keys that may occur in this subtree.
Validate a Binary Search Tree – Java Source Code
The second variant is most easily understood by reading the source code (BinarySearchTreeValidator class). The following variant does not allow key duplicates:
public static boolean isBstWithoutDuplicates(BinaryTree tree) {
return isBstWithoutDuplicates(tree.root, Integer.MIN_VALUE, Integer.MAX_VALUE);
}
private static boolean isBstWithoutDuplicates(
Node node, int minAllowedKey, int maxAllowedKey) {
if (node == null) {
return true;
}
if (node.data < minAllowedKey || node.data > maxAllowedKey) {
return false;
}
return isBstWithoutDuplicates(node.left, minAllowedKey, node.data - 1)
&& isBstWithoutDuplicates(node.right, node.data + 1, maxAllowedKey);
}Code language: GAUSS (gauss)We first pass the root node and the number range of all integer values to the recursive isBstWithoutDuplicates() method. The method checks if the key of the given node is in the allowed number range. If not, the method returns false.
If yes, the method is called recursively on the left and right subtree. Thereby the allowed number range is restricted more and more according to the BST properties.
A second variant of the method, which also allows key duplicates, can be found in the same class, starting at line 33.
Time Complexity of the Binary Search Tree
The time for searching, inserting, and deleting nodes grows linearly with the depth of the respective node since a comparison must be performed for each level that the node is away from the root.
In a balanced binary tree, we can discard about half of the tree at each comparison. The height of a balanced binary tree with n nodes – and thus also the time complexity for the search, insert and delete operation – is therefore of the order O(log n).
In a degenerate binary tree, the height corresponds to the number of nodes. The number of comparisons – and thus the time complexity for all operations – is thus of order O(n).
Binary Search Tree Comparison
In the following sections, you will find the advantages and disadvantages of the binary search tree compared to other data structures.
Binary Tree vs Binary Search Tree
A binary search tree is a special form of the binary tree in which the binary tree properties (see definition) are fulfilled.
Binary Search Tree vs Heap
In the following comparison of binary search tree and heap, I assume a balanced binary search tree. For a degenerate binary search tree, the given time complexities are correspondingly worse, namely O(n).
- In a binary search tree, it is possible to iterate over the keys in sort order. This is not directly possible in a heap.
- Insertion and deletion of elements are possible in both data structures with logarithmic time – O(log n).
- Searching for an element is associated with logarithmic overhead – O(log n) - in the binary search tree. Since the heap is not sorted, the only remaining option is to search all elements – that is, linear time, O(n).
- In a heap, you can access the largest (max-heap) or smallest (min-heap) element with constant time – O(1). A binary search tree requires following either all left children or all right children, which requires logarithmic time – O(log n).
- Building a heap can be done in linear time – O(n). Building a BST has a time complexity of O(n log n).
So when should which data structure be used?
The binary search tree is appropriate if you want to search for elements or iterate over all elements in sort order. If, on the other hand, you are only interested in the largest or smallest element, the heap is more suitable.
Binary Search Tree vs Hashtable
In this comparison, I again assume a balanced binary search tree. Hashtable denotes the abstract data structure. The comparison also applies, for example, to the concrete Java types HashMap and HashSet.
- In a binary search tree, it is possible to iterate over the keys in sort order. This is not possible in a hashtable.
- In a binary search tree, a range search is possible (i.e., the search for all elements that lie in a given value range). Since the hashtable is unsorted, this is not possible with it.
- In a hashtable, you can store only elements for which a hash function is defined. In a binary search tree, you can store only elements for which a comparison function is defined.
- "Bucket collisions" can occur in a hashtable. These have to be resolved with (more or less) complex algorithms during insertion and search.
- Insertion, search, and deletion are possible in a hashtable with constant time – O(1) – as long as the hashtable is sufficiently sized and a suitable hash function is used. For the binary search tree, the time complexity for all three operations is O(log n). Modern hashtables also use binary search trees within their buckets, so the time complexity also goes towards O(log n) for many collisions.
- A binary search tree is more efficient concerning the space requirement since it contains precisely one node per element. A hashtable usually also contains empty buckets.
When should a binary search tree be used and when a hashtable?
The binary search tree is suitable if you want to iterate over all elements in sort order or perform range searches. If you only want to insert, search and delete elements, you should use the hashtable, which is faster for these operations.
Binary Search vs Binary Search Tree
And last but not least (since it is often asked for):
- A binary search tree is a data structure as described in this article.
- Binary search, on the other hand, is an algorithm used to search a sorted list.
Conclusion
This tutorial has shown you what a binary search tree is and how to insert, search, and delete its elements. You've seen sample implementations in Java - one recursive and one iterative. And I've listed the differences between the binary search tree and other data structures.
In the following parts of the series, I will introduce you to the concrete BST implementations AVL tree and red-black tree. Do you want to be informed as soon as the articles go online? Then click here to sign up for the HappyCoders newsletter.
If you liked the article, feel free to share it using one of the share buttons at the end and leave me a comment.